Zookeeper Jute
1. 前言
在我们使用 Zookeeper 客户端和 Zookeeper 服务端建立连接,发送请求时,Zookeeper 客户端需要把请求协议进行序列化才能进行发送,Zookeeper 服务端接收到请求,还需要把请求协议进行反序列化才能解析请求,这样才完成了一次请求的发送。那么序列化是什么呢?我们为什么要使用序列化?Zookeeper 中又是如何使用序列化的呢?我们就带着这些问题开始本节的内容。
2. Zookeeper 序列化
在 Zookeeper 的通信与会话一节中,我们学习了 Zookeeper 使用的是基于 TCP 的通信协议,TCP 协议是一种面向连接的、可靠的、基于字节流的通信协议。
我们想要使用 Zookeeper 客户端向 Zookeeper 服务端发送请求,我们就需要把请求发送的 Java 对象转换为字节流的形式,这个转换的过程就是序列化。相对来说,把字节流转换为 Java 对象的过程就是反序列化。
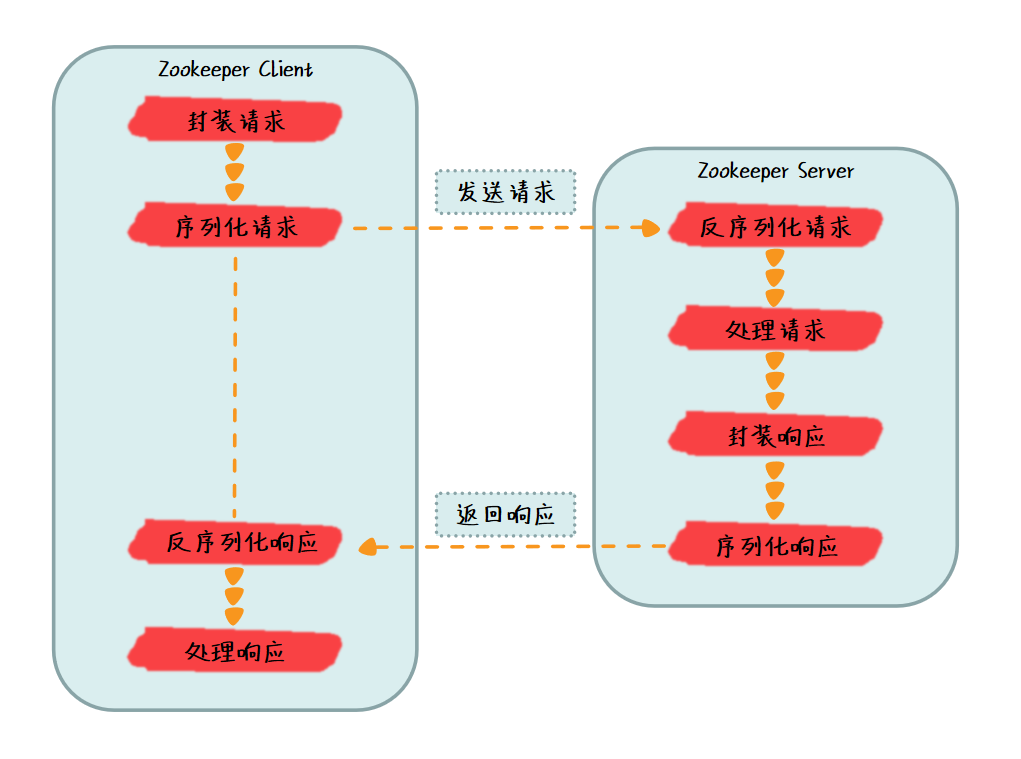
那么我们什么时候使用序列化呢?
- 对象需要持久化时;
- 对象进行网络传输时。
Zookeeper 的应用场景就需要大量的网络传输,所以需要使用序列化来提高 Zookeeper 客户端与服务端之间的通信效率。
在 Zookeeper 中,这一过程不需要我们自己去实现,无论是 Zookeeper 客户端还是 Zookeeper 服务端,都已经把序列化和反序列化的过程进行了封装。那么 Zookeeper 时如何实现序列化的呢?接下来我们就来介绍 Zookeeper 的序列化实现方式 Jute。
2.1 Jute 介绍
Jute 前身是 Hadoop Record IO 中的序列化组件,从 Zookeeper 第一个正式版,到目前最新的稳定版本 Apache ZooKeeper 3.6.1 都是用的 Jute 作为序列化组件。
为什么 Zookeeper 会一直选择 Jute 作为它的序列化组件呢?并不是 Jute 的性能比其他的序列化框架好,相反的,现在市面上有许多性能更好的序列化组件,比如 Apache Thrift,Apache Avro 等组件,性能都要优于 Jute。之所以还使用 Jute,是因为到目前为止,Jute 序列化还不是 Zookeeper 的性能瓶颈,没有必要强行更换,而且很难避免因为替换基础组件而带来的一系列版本兼容的问题。
简单的介绍了一下 Jute ,那么在 Zookeeper 中,Jute 又是如何实现的呢?接下来我们就来讲解 Jute 在 Zookeeper 中的实现。
2.2 Jute 实现
在 Zookeeper 的通信及会话一节中,我们学习了 Zookeeper 的请求协议和响应协议,并查看了部分源码。我们可以发现,无论是请求协议还是响应协议的具体类,都实现了接口 Record,Record 接口其实就是 Jute 定义的序列化接口。
package org.apache.jute;
import java.io.IOException;
import org.apache.yetus.audience.InterfaceAudience.Public;
@Public
public interface Record {
// 序列化
void serialize(OutputArchive var1, String var2) throws IOException;
// 反序列化
void deserialize(InputArchive var1, String var2) throws IOException;
}
我们这里使用请求头 RequestHeader 作为例子来查看序列化和反序列化的实现:
// 请求头,实现了 Record
public class RequestHeader implements Record {
private int xid;
private int type;
// 使用 OutputArchive 进行序列化,tag:序列化标识符
public void serialize(OutputArchive a_, String tag) throws IOException {
a_.startRecord(this, tag);
a_.writeInt(this.xid, "xid");
a_.writeInt(this.type, "type");
a_.endRecord(this, tag);
}
// 使用 InputArchive 进行反序列化,tag 序列化标识符
public void deserialize(InputArchive a_, String tag) throws IOException {
a_.startRecord(tag);
this.xid = a_.readInt("xid");
this.type = a_.readInt("type");
a_.endRecord(tag);
}
}
在 serialize 序列化方法中,根据成员变量的数据类型来选择 OutputArchive 的方法来进行序列化操作。在 deserialize 反序列化方法中,根据成员变量的数据类型来选择 InputArchive 的方法来进行反序列化操作。
在这里我们可以发现,Record 只是定义了序列化方法和反序列化方法,真正执行序列化操作是 OutputArchive 和 InputArchive 这两个接口的实现类。接下来我们讲解 OutputArchive 序列化接口的实现类 BinaryOutputArchive。
2.3 BinaryOutputArchive
BinaryOutputArchive 是二进制的序列化方式,这种方式将 Java 对象转化成二进制的格式来进行数据传输。在它的具体方法中,使用的是 java.io.DataOutputStream 的方法来完成 Java 对象到二进制的转换,我们来看看具体实现:
/\*\*
\* 二进制的序列化
\*/
public class BinaryOutputArchive implements OutputArchive {
// 定义字节缓冲区大小
private ByteBuffer bb = ByteBuffer.allocate(1024);
// 数据输出接口 DataOutput
private DataOutput out;
// 使用 OutputStream 初始化 BinaryOutputArchive
public static BinaryOutputArchive getArchive(OutputStream strm) {
return new BinaryOutputArchive(new DataOutputStream(strm));
}
// 构造方法传入 DataOutput
public BinaryOutputArchive(DataOutput out) {
this.out = out;
}
// 输出 byte 类型为二进制
public void writeByte(byte b, String tag) throws IOException {
this.out.writeByte(b);
}
// 输出 boolean 类型为二进制
public void writeBool(boolean b, String tag) throws IOException {
this.out.writeBoolean(b);
}
// 输出 int 类型为二进制
public void writeInt(int i, String tag) throws IOException {
this.out.writeInt(i);
}
// 输出 long 类型为二进制
public void writeLong(long l, String tag) throws IOException {
this.out.writeLong(l);
}
// 输出 float 类型为二进制
public void writeFloat(float f, String tag) throws IOException {
this.out.writeFloat(f);
}
// 输出 double 类型为二进制
public void writeDouble(double d, String tag) throws IOException {
this.out.writeDouble(d);
}
// 工具方法:字符串转字节缓冲区
private ByteBuffer stringToByteBuffer(CharSequence s) {
this.bb.clear();
int len = s.length();
for(int i = 0; i < len; ++i) {
if (this.bb.remaining() < 3) {
ByteBuffer n = ByteBuffer.allocate(this.bb.capacity() << 1);
this.bb.flip();
n.put(this.bb);
this.bb = n;
}
char c = s.charAt(i);
if (c < 128) {
this.bb.put((byte)c);
} else if (c < 2048) {
this.bb.put((byte)(192 | c >> 6));
this.bb.put((byte)(128 | c & 63));
} else {
this.bb.put((byte)(224 | c >> 12));
this.bb.put((byte)(128 | c >> 6 & 63));
this.bb.put((byte)(128 | c & 63));
}
}
this.bb.flip();
return this.bb;
}
// 输出 String 类型为二进制
public void writeString(String s, String tag) throws IOException {
if (s == null) {
this.writeInt(-1, "len");
} else {
// String 不为空转字节缓冲区
ByteBuffer bb = this.stringToByteBuffer(s);
this.writeInt(bb.remaining(), "len");
// 输出 字节数组
this.out.write(bb.array(), bb.position(), bb.limit());
}
}
// 输出 字节数组为二进制
public void writeBuffer(byte[] barr, String tag) throws IOException {
if (barr == null) {
this.out.writeInt(-1);
} else {
this.out.writeInt(barr.length);
this.out.write(barr);
}
}
}
介绍了序列化的具体实现类,接下来就是反序列化接口 InputArchive 的实现类 BinaryInputArchive。
2.4 BinaryInputArchive
BinaryInputArchive 是二进制的反序列化,也就是把二进制格式转换成 Java 对象。在它的具体方法中,使用了 java.io.DataOutputStream 的方法来完成二进制格式到 Java 对象的转换,我们来看具体实现:
package org.apache.jute;
import java.io.DataInput;
import java.io.DataInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.charset.StandardCharsets;
/\*\*
\* 二进制的反序列化
\*/
public class BinaryInputArchive implements InputArchive {
// 长度异常的字符串
public static final String UNREASONBLE_LENGTH = "Unreasonable length = ";
// 最大缓冲区
public static final int maxBuffer = Integer.getInteger("jute.maxbuffer", 0xfffff);
// 额外的最大缓冲区
private static final int extraMaxBuffer;
static {
final Integer configuredExtraMaxBuffer =
Integer.getInteger("zookeeper.jute.maxbuffer.extrasize", maxBuffer);
if (configuredExtraMaxBuffer < 1024) {
extraMaxBuffer = 1024;
} else {
extraMaxBuffer = configuredExtraMaxBuffer;
}
}
// 数据输入接口 DataInput
private DataInput in;
// 最大缓冲区的大小
private int maxBufferSize;
// 额外的最大缓冲区的大小
private int extraMaxBufferSize;
// 使用 InputStream 实例化 BinaryInputArchive
public static BinaryInputArchive getArchive(InputStream strm) {
return new BinaryInputArchive(new DataInputStream(strm));
}
private static class BinaryIndex implements Index {
private int nelems;
BinaryIndex(int nelems) {
this.nelems = nelems;
}
public boolean done() {
return (nelems <= 0);
}
public void incr() {
nelems--;
}
}
// 构造方法
public BinaryInputArchive(DataInput in) {
this(in, maxBuffer, extraMaxBuffer);
}
// 构造方法
public BinaryInputArchive(DataInput in, int maxBufferSize, int extraMaxBufferSize) {
this.in = in;
this.maxBufferSize = maxBufferSize;
this.extraMaxBufferSize = extraMaxBufferSize;
}
// 读取二进制到 Byte 类型
public byte readByte(String tag) throws IOException {
return in.readByte();
}
// 读取二进制到 Boolean 类型
public boolean readBool(String tag) throws IOException {
return in.readBoolean();
}
// 读取二进制到 int 类型
public int readInt(String tag) throws IOException {
return in.readInt();
}
// 读取二进制到 long 类型
public long readLong(String tag) throws IOException {
return in.readLong();
}
// 读取二进制到 float 类型
public float readFloat(String tag) throws IOException {
return in.readFloat();
}
// 读取二进制到 double 类型
public double readDouble(String tag) throws IOException {
return in.readDouble();
}
// 读取二进制到 String 类型
public String readString(String tag) throws IOException {
int len = in.readInt();
if (len == -1) {
return null;
}
checkLength(len);
byte[] b = new byte[len];
in.readFully(b);
return new String(b, StandardCharsets.UTF_8);
}
// 读取二进制到字节数组
public byte[] readBuffer(String tag) throws IOException {
int len = readInt(tag);
if (len == -1) {
return null;
}
checkLength(len);
byte[] arr = new byte[len];
in.readFully(arr);
return arr;
}
}
3. 总结
在本节内容中我们学习了什么是序列化,为什么要使用序列化来进行数据传输, 以及 Zookeeper 的序列化方式 Jute 的具体实现。以下是本节内容总结:以下是本节内容总结:
- 什么是序列化。
- 什么时候使用序列化。
- Zookeeper 的序列化方式 Jute。